![[alt: Code comparison graphic highlighting Speechmatics for speech-to-text accuracy; includes logos, text, and a dark theme.]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F596R900g43VkgyyNNvEbcc%2F014280621b0903658176e2525c189a7a%2Faws-Hero-image.webp&w=3840&q=75)








See how Speechmatics compares vs AWS on your audio
See how Speechmatics compares vs AWS on your audio
Choose from live radio, your own voice, or sample audio to see side-by-side comparisons of Speechmatics vs Amazon Transcribe.
Why enterprises choose Speechmatics over AWS
Why enterprises choose Speechmatics over AWS

Built for real-world audio
Speechmatics is built for real-world conditions — noisy backgrounds, diverse accents, and challenging audio — with a global, accent-inclusive approach to building every language, not just clean recordings. It holds a 4.8/5 G2 rating versus Amazon Transcribe’s 3.9/5 (Spring 2026).

One model, every accent
Speechmatics uses 53+ production-proven languages, each with a single inclusive model that recognizes every regional variant. Amazon Transcribe needs a separate model per dialect — one for US English, one for UK English, one for Welsh, and so on.

Independent — and built only for speech
Speechmatics’ only business is speech. You get true on-premises deployment with no AWS lock-in, freedom to run in any cloud or none, and dedicated Customer Success and Sales Engineers for enterprise — not a ticket queue behind thousands of other services.
Speechmatics vs AWS: Feature-by-feature comparison
Speechmatics vs AWS: Feature-by-feature comparison
A detailed look at how the two platforms stack up across core capabilities, deployment options, and verified public reviews.
Feature | Speechmatics ★ | Amazon Transcribe |
|---|---|---|
Flagship Model | Ursa 2 (Standard & Enhanced), plus recently launched Melia for multilingual — fully proprietary | Amazon Transcribe — part of the broader AWS ecosystem |
Language & Accent Approach | One inclusive model per language covers all regional variants | Separate model per dialect (US, UK, Welsh, Irish English, etc.) |
Multi-Language Detection | Auto-detects multiple languages within a single stream | Limited; customers often must supply a list of expected languages as a hint |
Real-Time Transcription | ✓ Yes | ✓ Yes |
Batch Transcription | ✓ Yes | ✓ Yes |
Real-Time Latency | Sub-1 second; finals at ~700ms | Higher latency reported in production workloads |
Speaker Diarisation | ✓ Real-time diarization; channel diarization available | Voice-print speaker detection less reliable; frequent diarization errors reported |
Custom Dictionary & Phonetics | ✓ Phonetic prompts supported, no model retraining | Custom vocabulary available, but no phonetic support |
Medical / Domain Models | Dedicated medical uplift models (English, French, German, Spanish, Arabic-English) — available globally | HealthScribe / Transcribe Medical: US English (en-US) only |
On-Premises Deployment | ✓ Mature, production-ready | Primarily cloud; limited on-premises options |
On-Device Deployment | ✓ Yes | ✗ No |
Air-Gapped Deployment | ✓ Yes | ✗ No |
Data Privacy | True on-prem — air-gapped networks supported; no data leaves your environment | Cloud-dependent |
Pricing | From $0.129/hr (Melia batch) | From $1.44/hr (Tier 1); volume discounts only above 250K min/mo |
ISO 27001 / SOC2 / HIPAA / GDPR | ✓ All four | ✓ Yes / ✓ Yes / ✓ Yes / ✓ Yes |
G2 Spring 2026 — Head-to-Head
Metric | Speechmatics ★ | Amazon Transcribe |
|---|---|---|
Overall G2 Rating | 4.8 / 5 (52 reviews) | 3.9 / 5 (16 reviews) |
Likelihood to Recommend | 96% | 79% |
Product Direction (% positive) | 98% | 73% |
Good Partner in Doing Business | 95% | 83% |
Meets Requirements | 91% | 78% |
Quality of Support | 91% | 77% |
Ease of Use | 94% | 81% |
Ease of Setup | 91% | 77% |
Ease of Admin | 91% | 75% |
Average Time to ROI | 3 months | 12 months |
Average Go-Live Time | 1 month | 3 months |
Where Speechmatics outperforms AWS
Where Speechmatics outperforms AWS
Real-Time ASR | Enterprise Differentiation | Competitive Positioning
Accuracy in real-world conditions
Speechmatics is built for real-world audio — noisy backgrounds, diverse accents, and challenging conditions. It holds a 4.8/5 G2 rating versus Amazon Transcribe’s 3.9/5, with a global, accent-inclusive approach to every language.
Single model, every accent
Amazon Transcribe needs a separate model per dialect — US, UK, Welsh, Irish English and beyond. One Speechmatics model captures the root language and all its global variants, in one.
Global medical models
Speechmatics offers dedicated medical uplift models in English, French, German, Spanish, and Arabic-English, available globally. AWS HealthScribe and Transcribe Medical are US English only — a hard stop for international healthcare.
Best-in-class real-time diarization
Speechmatics delivers reliable real-time speaker diarization, with channel diarization also available. Amazon Transcribe’s speaker detection is a frequent customer pain point, with diarization errors a common reason teams switch.
A specialist, not a hyperscaler
Speechmatics runs in true on-premises containers (CPU-capable, air-gapped) with no AWS lock-in, plus dedicated Customer Success and Sales Engineers. Speech is our entire business, not one of thousands of services.
Lower entry cost & simpler pricing
Speechmatics starts from $0.129/hr (Melia batch). Amazon Transcribe starts at $1.44/hr, the same for real-time and batch, with volume discounts only kicking in above 250K minutes a month — a high barrier for most teams.
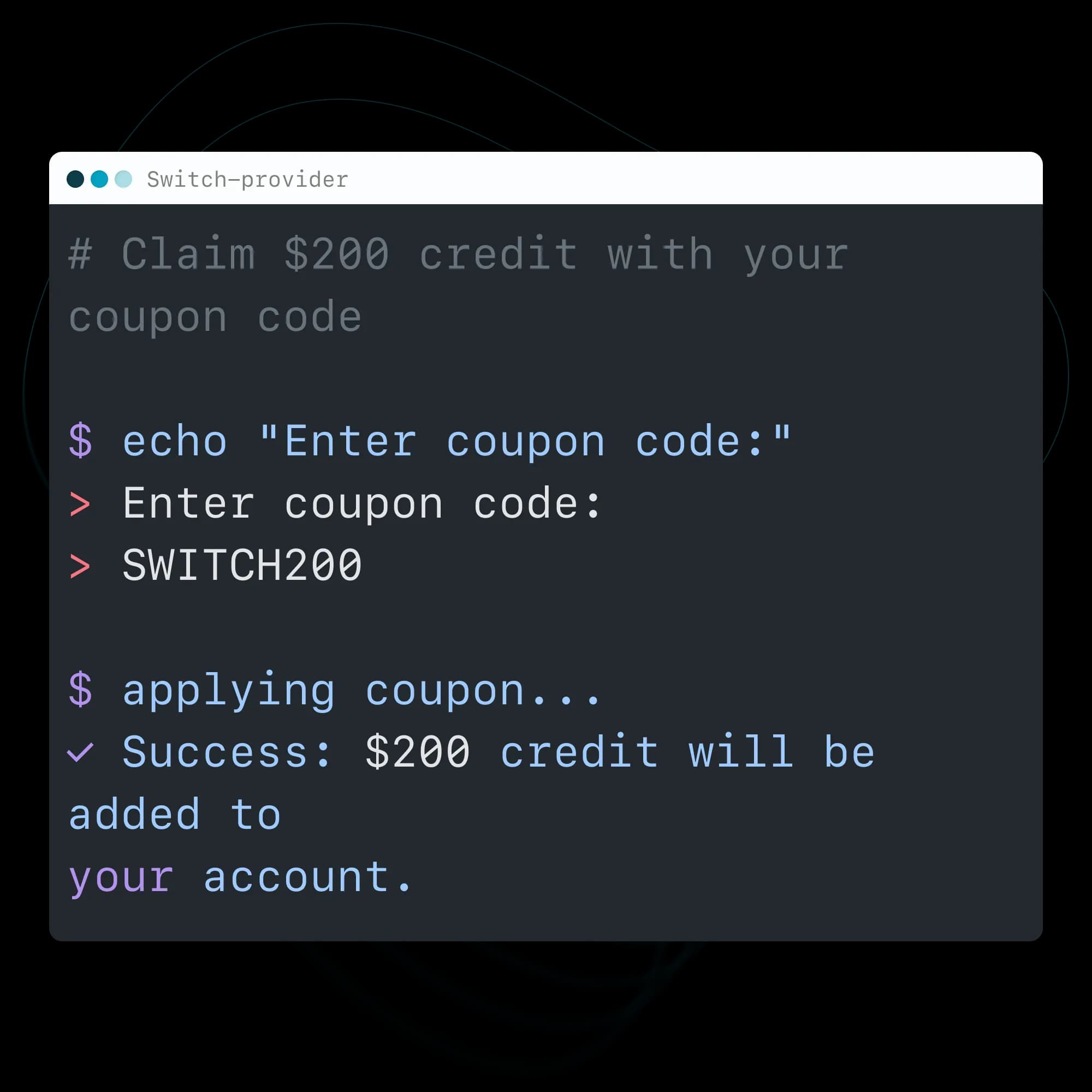
Start building with Speechmatics today
1) 👤 Log in or signup to the Speechmatics Portal
2) 💳 Add a valid payment card (no charge until credit is used)
3) 🔑 Enter your code: SWITCH200
4) 🚀 Start building with $200 free credit
Frequently Asked Questions: Speechmatics vs AWS
Is Speechmatics more accurate than Amazon Transcribe?
Is Speechmatics more accurate than Amazon Transcribe?
In real-world conditions, yes. Speechmatics is built for noisy audio and diverse accents, and holds a 4.8/5 G2 rating versus Amazon Transcribe’s 3.9/5 (Spring 2026). Where general-purpose cloud models degrade with background noise and accents, Speechmatics takes a global, accent-inclusive approach to building every language.
Does Speechmatics handle accents and dialects better than Amazon Transcribe?
Does Speechmatics handle accents and dialects better than Amazon Transcribe?
Speechmatics uses a single inclusive model per language that recognizes every regional variant — UK, Irish, Welsh, Scottish, Indian, Australian and Singaporean English, all in one model. Amazon Transcribe typically requires a separate model per dialect (one for US English, one for UK English, one for Welsh English, and so on), which adds complexity for global operations.
Does Amazon Transcribe support medical models outside the US?
Does Amazon Transcribe support medical models outside the US?
No. AWS HealthScribe and Amazon Transcribe Medical support US English (en-US) only and are limited to a US region. Speechmatics offers dedicated medical uplift models across English, French, German, Spanish, and Arabic-English bilingual, available globally — a major advantage for international healthcare deployments.
How does Speechmatics pricing compare to Amazon Transcribe?
How does Speechmatics pricing compare to Amazon Transcribe?
Both providers price by usage. Speechmatics starts from $0.129/hr (Melia batch). Amazon Transcribe starts at $1.44/hr (Tier 1, the same for real-time and batch), and its volume discounts only begin above 250,000 minutes per month — a high barrier for most teams.
How does speaker diarization compare to Amazon Transcribe?
How does speaker diarization compare to Amazon Transcribe?
Speechmatics offers best-in-class real-time speaker diarization, with channel diarization also available. Amazon Transcribe’s speaker detection is a recurring pain point, with customers reporting frequent diarization errors. Reliable speaker separation is one of the most common reasons teams switch to Speechmatics.
Can Speechmatics detect multiple languages in a single audio stream?
Can Speechmatics detect multiple languages in a single audio stream?
Yes. Speechmatics can auto-detect multiple languages present in a single stream. Amazon Transcribe is not strong at auto-detecting when multiple languages appear in one recording, so customers often have to supply a list of expected languages as a hint.
Can Speechmatics be deployed on-premises?
Can Speechmatics be deployed on-premises?
Yes. Speechmatics offers true on-premises containers that you orchestrate and scale yourself, can run entirely on CPU infrastructure, and can be deployed offline in secure, air-gapped networks. Amazon Transcribe is primarily a cloud service with limited on-premises options.
Can I switch from Amazon Transcribe to Speechmatics easily?
Can I switch from Amazon Transcribe to Speechmatics easily?
Yes. Speechmatics offers a straightforward REST API and WebSocket interface for real-time transcription. To help you evaluate the switch, we are offering $200 in free credits with the code SWITCH200, plus hands-on migration support from our customer success team.
Resources for AI Voice Agents
![[alt: Vapi integration launch blog social asset]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F5rvEvjLDjyosWx3mVI7L76%2Fbacc01b541e87a90558373ca7b16d539%2FVapi-blog-assets-V1-Social-sharing.png&w=3840&q=75)
Vapi and Speechmatics: Build agents that understand every voice
Ship Voice AI agents that stay readable in real time, even in noisy, multi-speaker calls.
![[alt: Livekit and Speechmatics partnership]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2F55uo621nIAzecVIcDsrrGX%2Fa81809b4dcf9acd1883ce628f8a10552%2FLiveKit-blog_assets-V1_-_Header_16-9.webp&w=3840&q=75)
Introducing real-time, speaker-aware Voice Agents with LiveKit + Speechmatics
Speechmatics brings speaker diarization to LiveKit agents - enabling them to understand not just what was said, but who said it.
![[alt: The Pipecat logo]](/_next/image?url=https%3A%2F%2Fimages.ctfassets.net%2Fyze1aysi0225%2FpvtJ7dqMe5Kdfc6zSeyxI%2F173057fb186137baa7c5c1126e8e62da%2FSocial_sharing.png&w=3840&q=75)
Pipecat and Speechmatics: Building Voice Agents that know exactly ‘Who’ said ‘What’
Build smarter voice agents on Pipecat with Speechmatics speech-to-text, now with powerful speaker diarization for real-world, multi-speaker conversations.

How to build a conversational agent in less time than Cupid’s arrow takes to strike
What happens when you set out to build a fully functioning AI love guru with very little turnaround time? Let's find out...